基于卷积神经网络(CNN)的视觉识别
挑战
- 视觉点变化,观察的视角差异
- 规模尺度变化,巨人与小恶魔
- 内容可能是形态可变化的,扭曲的猫
- 观察物被遮挡
- 光照条件影响及其大
- 背景图像的影响
- 类型内的影响,比如‘主持人’这一分类范围较广
图片分类流程:
- 输入:N张图片组成的数据集,每张图片有一个明确的label
- 学习:利用数据集去学习每个label的特征,称之为“训练一个分类器”或“学习一个模型”
- 评估:用新的数据集去测试训练好的分类器,计算准确率
Nearest Neighbor Classifier
最近邻分类器和CNN无关、也极少用于实践,但能帮我们了解图片分类问题
思路:对于训练集,读取成为长*宽*3的矩阵。对于测试集,与前面训练集中的图片比较,找出与其最相似的图片则他们分为一类
图片比较方法:
1、计算两矩阵中对应两两位置的差值的和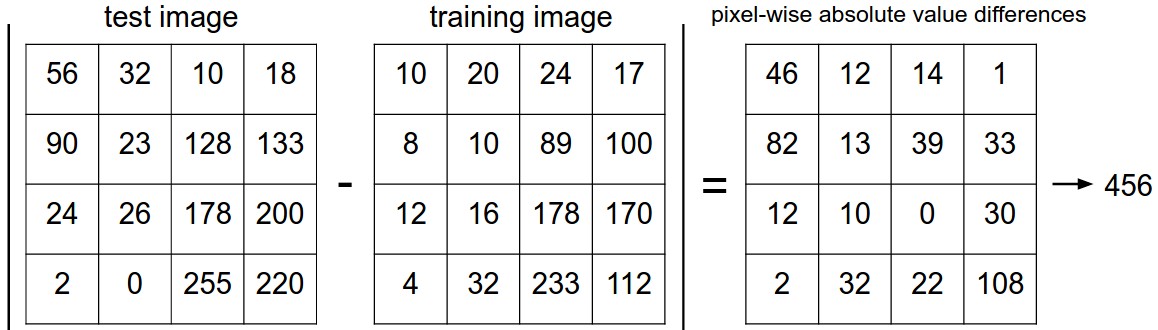
2、计算两矩阵中对应两两位置的差值的平方和然后再开根号1
Evaluate on the test set only a single time, at the very end.
1 | 将您的训练集分成训练集和验证集。使用验证集来调整所有超参数。最后在测试集上运行一次并报告性能。 |
Nearest Neighbor Classifier 的优缺点:优点:简单易懂,低训练成本。缺点:测试成本过高。逐像素距离根本不对应于感知或语义相似性。
交叉验证
在给定的建模样本中,拿出大部分样本进行建模型,留小部分样本用刚建立的模型进行预报,并求这小部分样本的预报误差,记录它们的平方加和。这个过程一直进行,直到所有的样本都被预报了一次而且仅被预报一次。把每个样本的预报误差平方加和,称为PRESS(predicted Error Sum of Squares)。